沉下心来分析HashMap的源码
HashMap的源码在JDK 1.7 的时候,还算是可以看的比较的明白,1.8后引入了红黑树,就变得看的费劲了。 所以这次尽可能详细的注释源码,也为这块做一个总结。
粗略的印象
首先是最初的图:
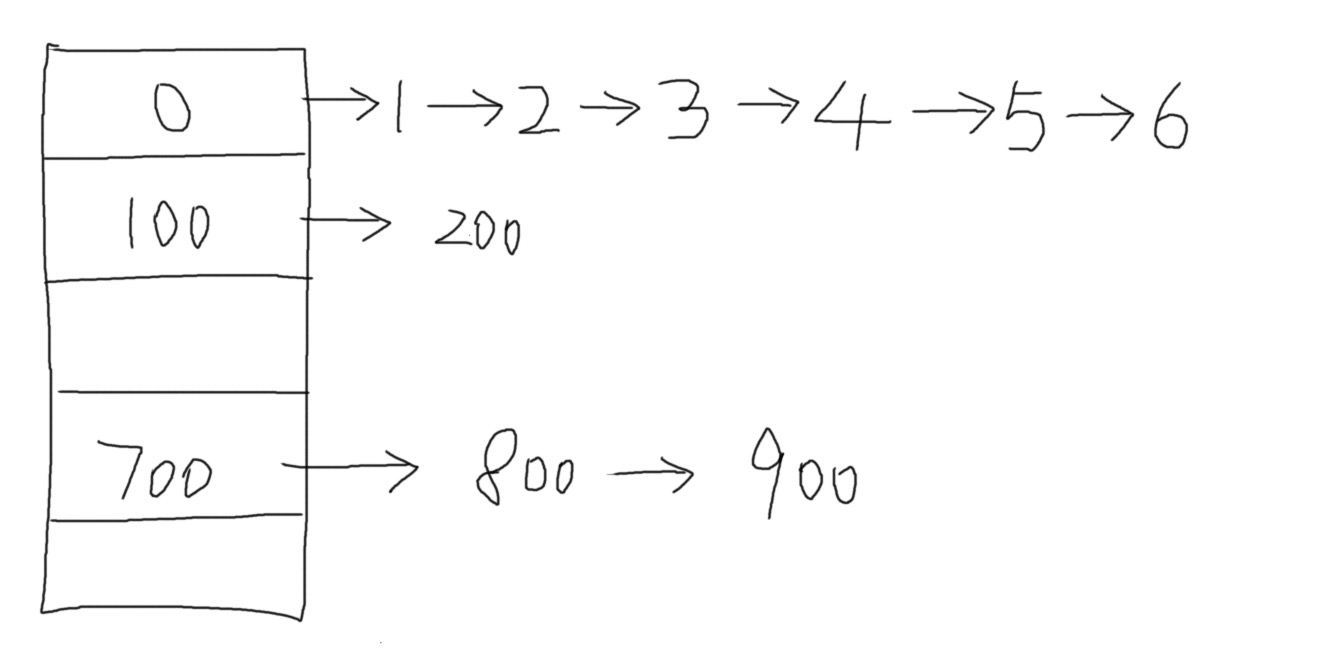
这个是我们以前常见的map的数据结构:桶,也可以称之为链表数组。但是1.8以后,在某些特殊的情况下,链表会和红黑树相互的转化,变成下面的这种数据结构:
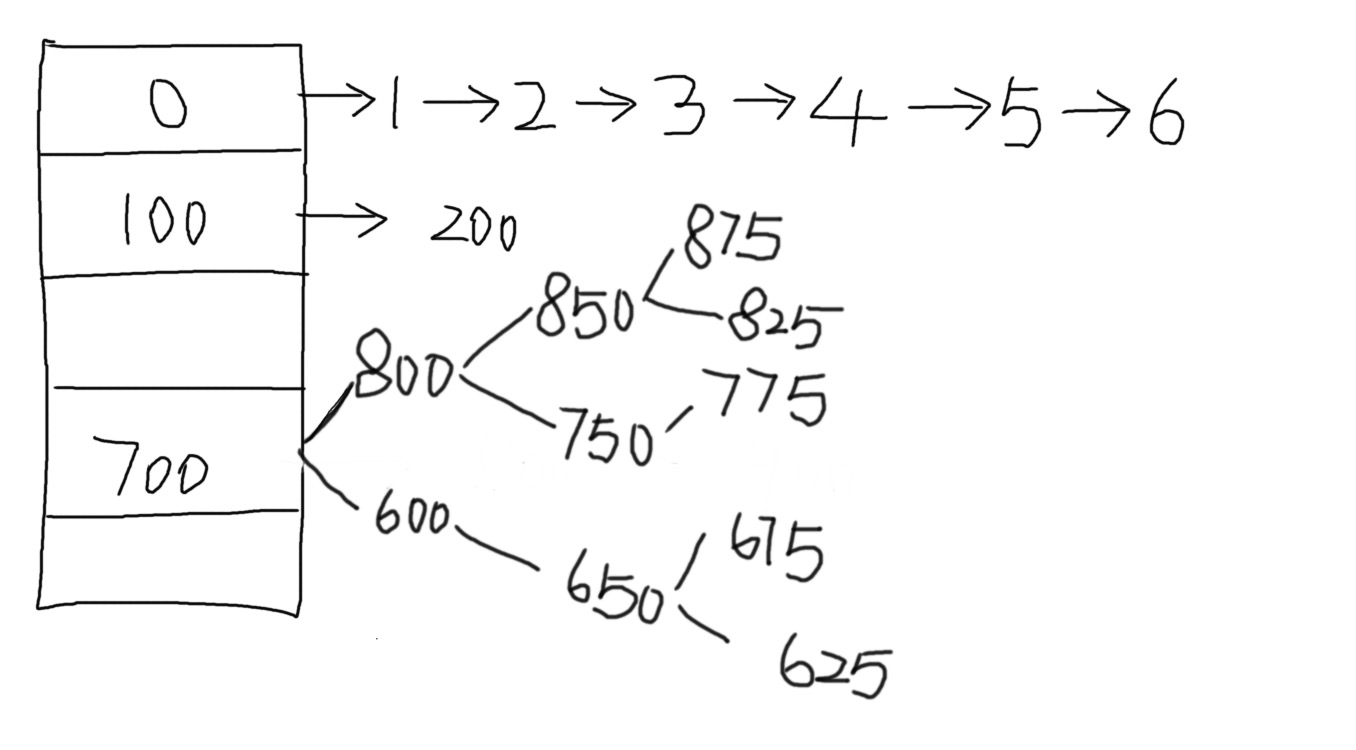
准备工作
但是具体是如何转化的,如何实现的,我们需要跟踪代码,进行详细的跟踪。 为了调试和注释的方便,我重写了hash的算法:
/**
* 3288498===> 3288448
*
* 1100100010110110110010
* 0000000000000000110010
* 1100100010110110000000
*
* 高中低位的字符全部的参与进来,把key的hash值打散
*/
static final int hash(Object key) {
// int h;
// return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
/**
* 为了测试,hash值一律的返回0
* */
return 0;
}
这样的话,全部的元素都会添加到桶的第一个位置上,把数据的变化表现的更加详尽。
测试代码
暂时先看Map最主要的两个操作,PUT和REMOVE,因为这两个操作针对的都是元素的增加和减少,在这个过程中能够看到数据结构的变化。
测试的代码如下:
public static void main(String[] args) {
//正经的测试
MyMap<String, String> mymap = new MyMap<String, String>();
for (int i = 0; i < 12; i++) {
mymap.put("k"+i, "v"+i);
}
System.out.println(mymap.table.length);
mymap.remove("k5");
for (int i = 4; i < 7; i++) {
mymap.remove("k"+i);
}
}
数据结构的准备工作:
从小到大的来说,首先是 Key 和 Value 组成键值对的表示 Node节点,Node节点表示为链表的节点,所以就有了next的属性。
public static class Node<K,V> {
public final int hash; // 包含一个hash值
public final K key;
public V value;
public Node<K,V> next; // 指向下一个节点
然后就是红黑树节点的表示,具有left,right,red之类的标志性属性,不过在HashMap中,红黑树的节点是Node的子类,主要是为了转换的方便,后面的代码中可以看到。
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
从这个我们还可以看到,不仅有right ,left,red,还有parent,pre属性。
最后就是存储节点的数组的数据结构:
// 非序列化
transient Node<K,V>[] table;
TreeNode继承自Node,在数组的表述中直接的声明Node节点即可。
PUT操作
代码的注释已经非常的详细,我会在代码的操作的过程中添加对应的图示,以便于更加明白的说明:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
期中的 hash(key) 经过了改写,全部的返回0,这样数据结构变化的会更加的明显,但是在原始的HashMap肯定不是这样的,如hash方法中的注释一样,原始的hash注重散列的均匀度。
/**
* Implements Map.put and related methods.
* put逻辑:
* 1. 检查hashmap中的table是否需要扩容
* 2.1 确定放入的值的位置:(n - 1) & hash,hash的计算方式:(h = key.hashCode()) ^ (h >>> 16)
* 2.2 如果该位置没有值,直接的新建Node,设置key,value值,放入table
* 2.3 如果该位置有Node值,判断key值有否相同
* 2.3.1 相同则是替换value值
* 2.3.2 不相同则是判断Node值的类型
* 2.3.2.1 如果Node值的类性是:TreeNode,标识为一颗红黑树的类型,调用putTreeVal
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n,/* n 代表的是原始的hashmap中 table 的 length值*/ i;
if ((tab = table) == null || (n = tab.length) == 0)
//扩容
n = (tab = resize()).length;
// & 值的运算:得到的值只可能比n-1小,如果table[i]为null,直接的赋值即可。
if ((p = tab[i = (n - 1) & hash]) == null) //①
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e;
K k;
// p=table[i]; hash值相同,k值和p的key值一样,直接的替换
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))//②
//替换value值
e = p;
else if (p instanceof TreeNode)//③
// 如果有值,并且Node的类型是TreeNode类型,调用TreeNode的putTreeVal
// TODO 暂时的放弃这个分支的分析
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// ④
// 如果不是TreeNode,那就是一个链表的类型
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果达到了7个,开始变换数据结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//传入的参数竟然是table和hash值
treeifyBin(tab, hash);
break;
}
//4.2
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
- 上一篇 怎么读书
- 下一篇 沉下心来分析HashMap的源码(二)